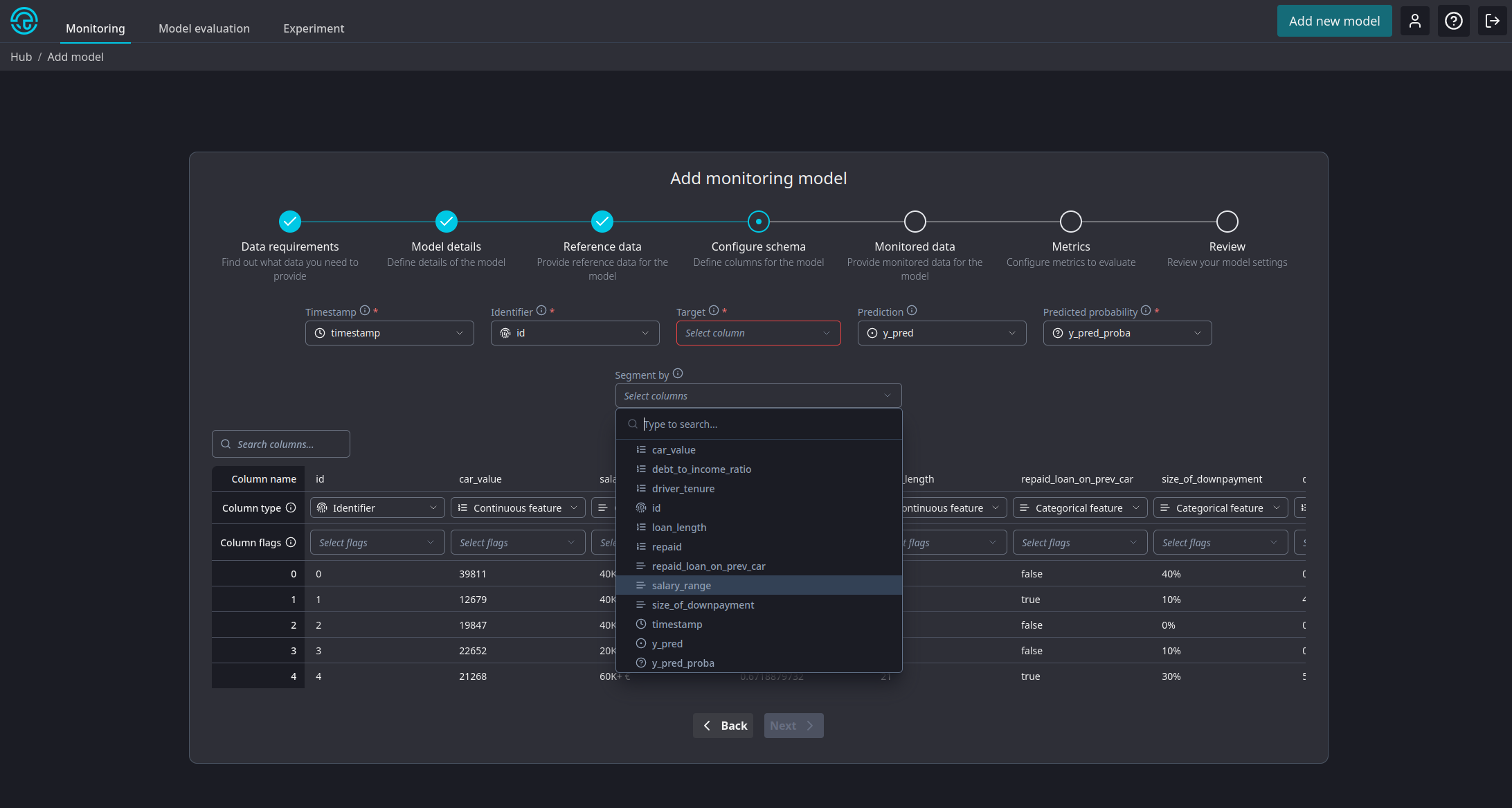
Marking a column as a segment source
Marking a column as a segment source
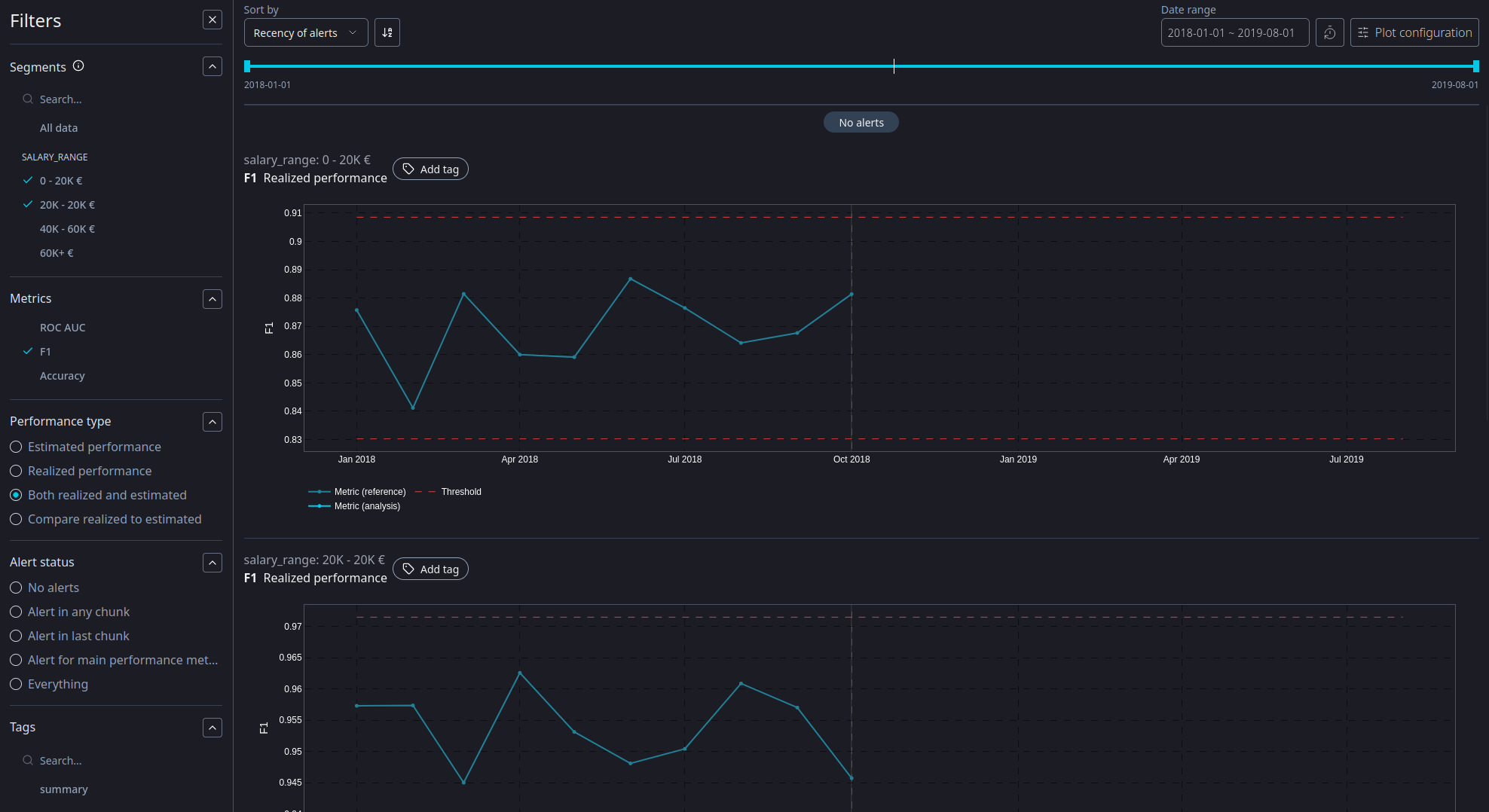
Applying segment filters
Selecting data sources, very fancy!
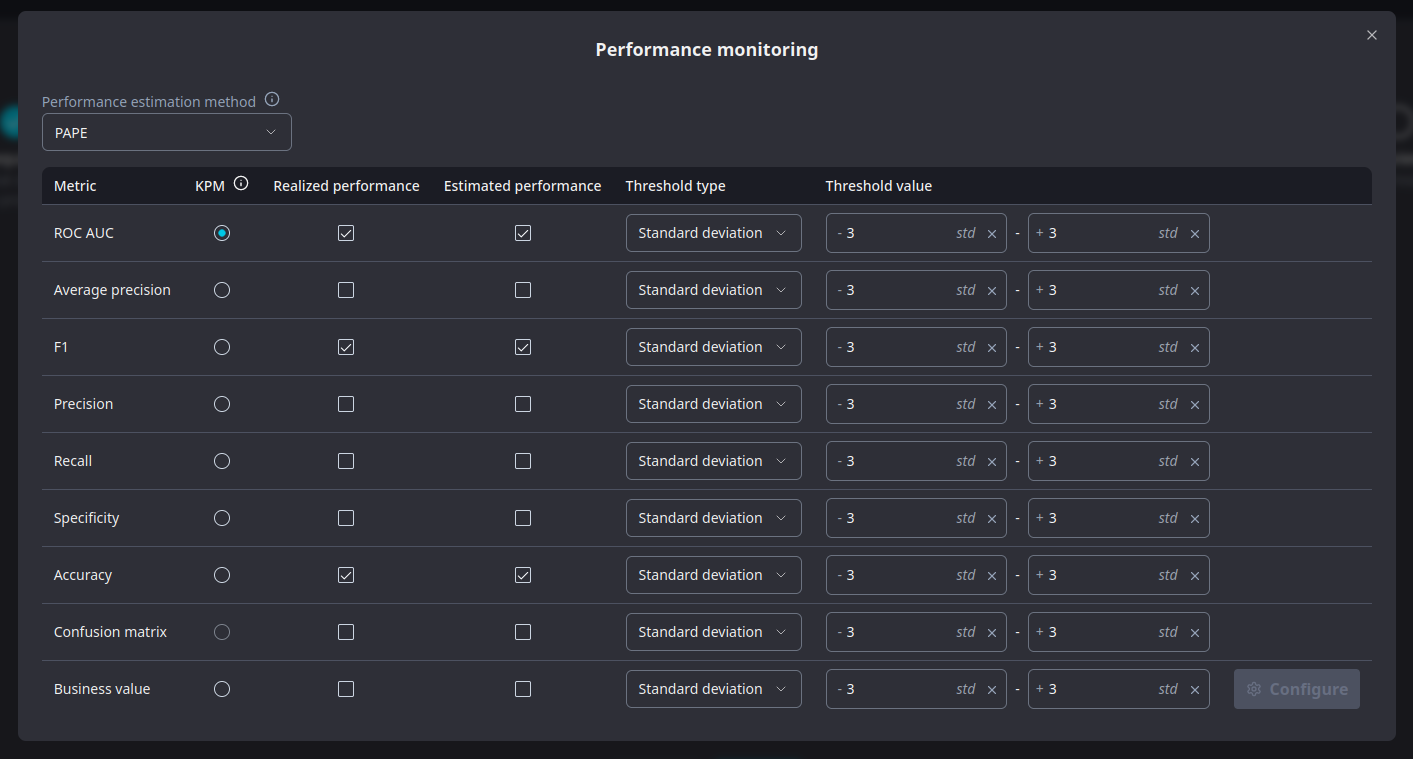
Configuring performance metrics during model creation
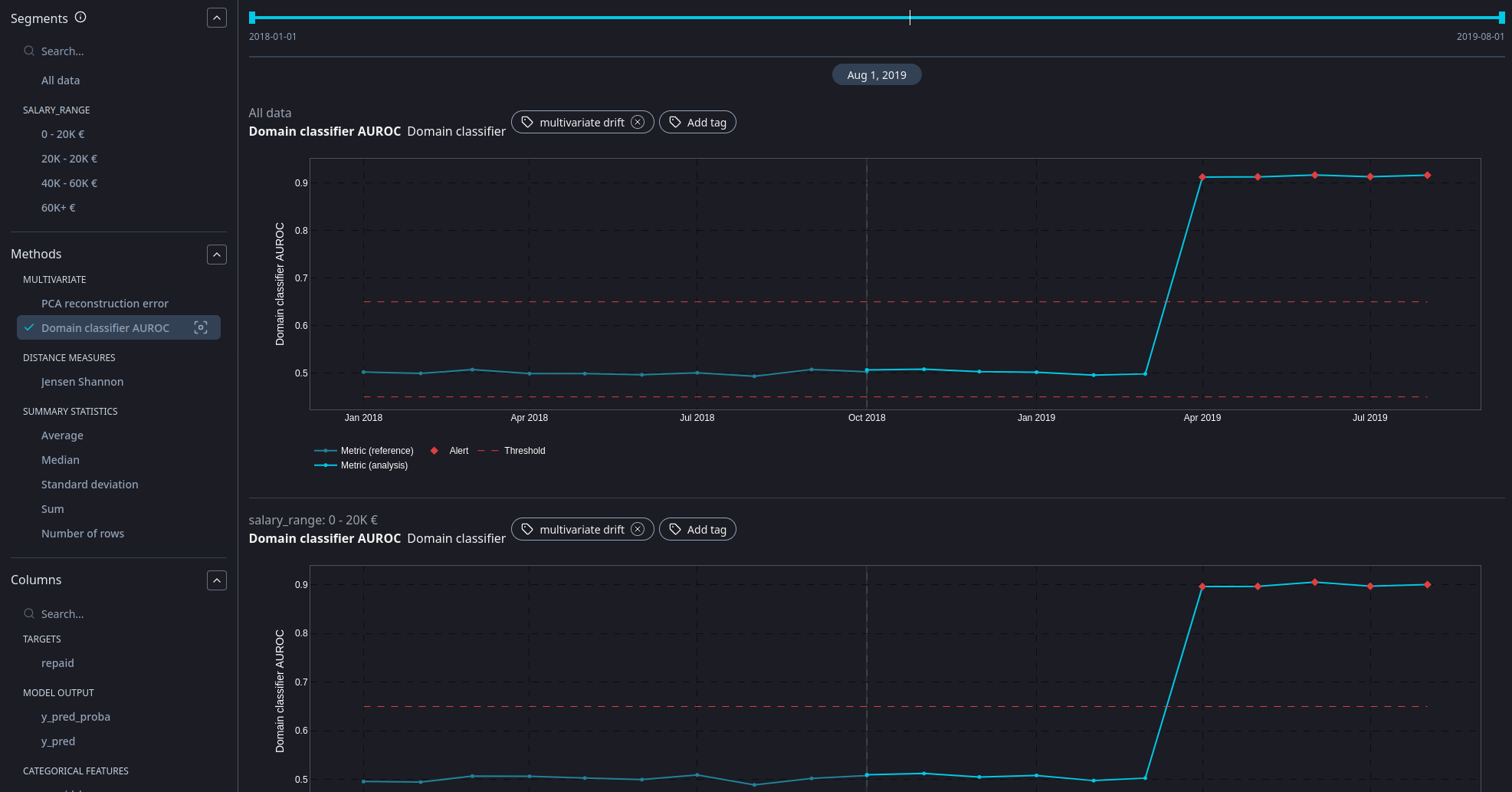
Multivariate drift detection with the domain classifier method
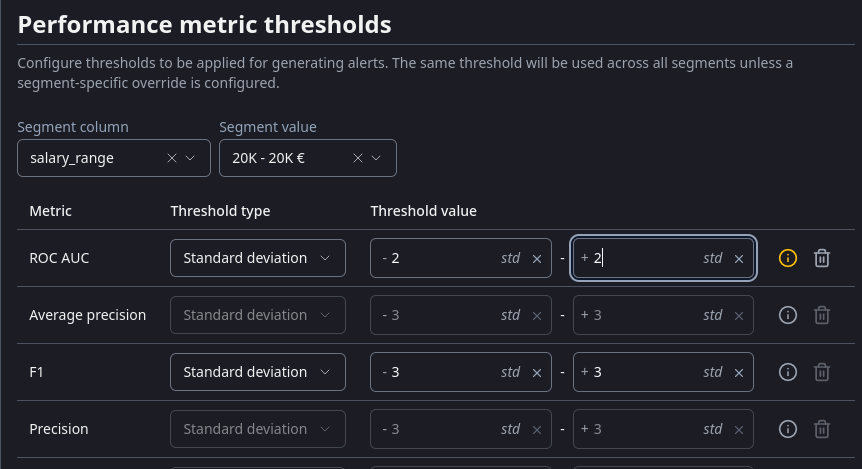
Look ma, no recalculation!