{kind=link}
{kind=link}
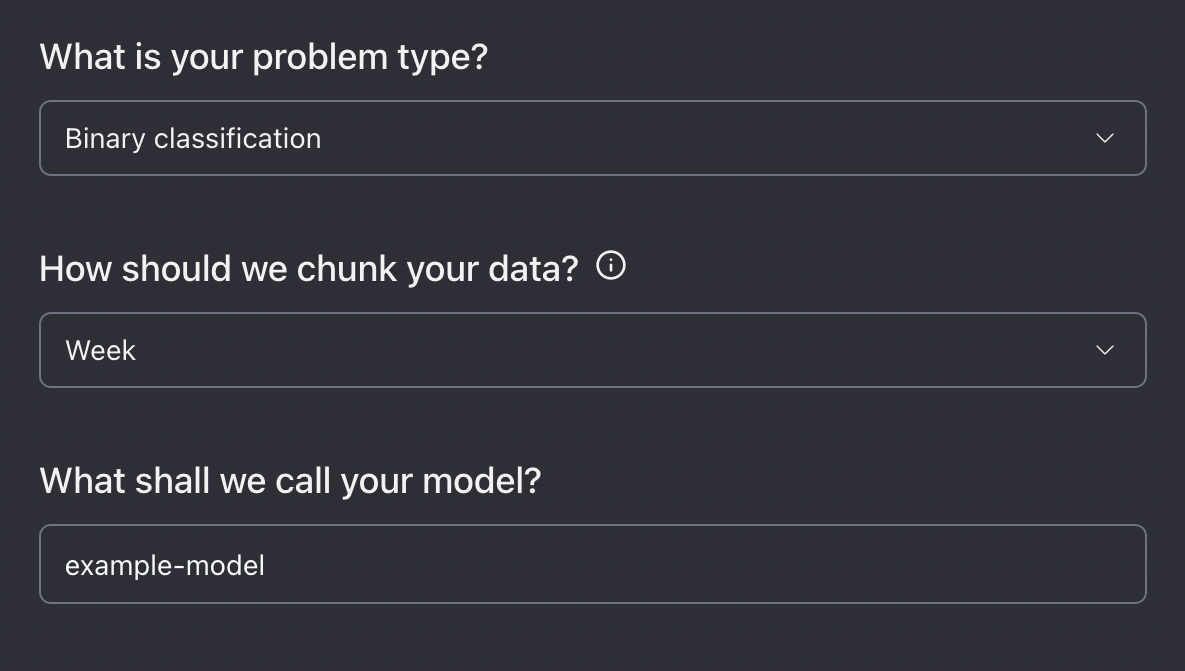
New model configuration setup.
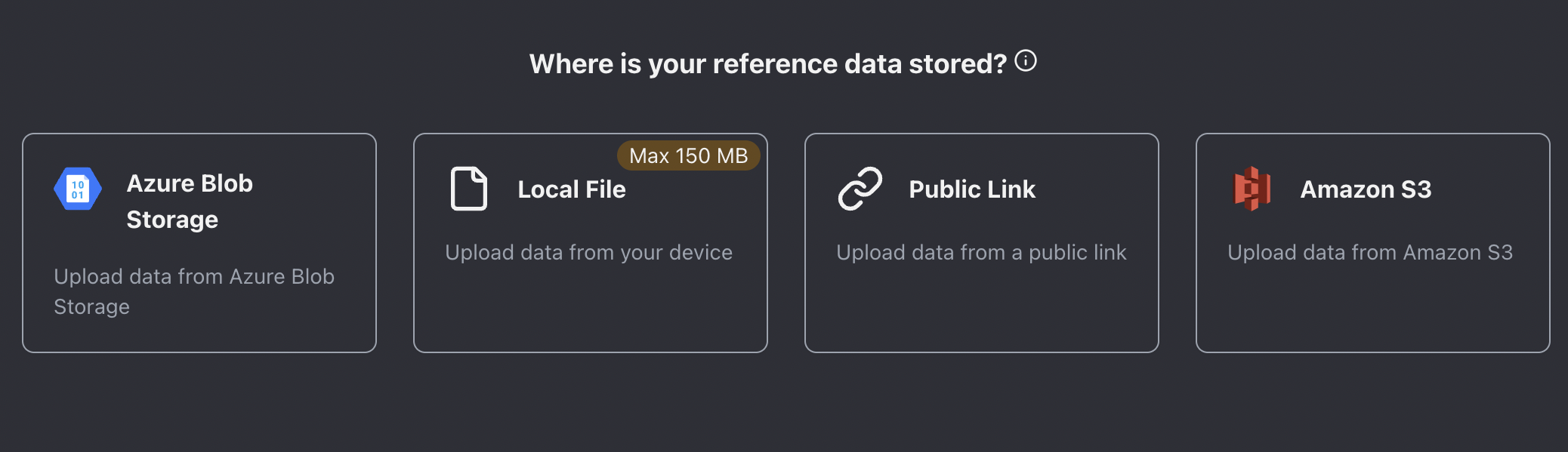
Data upload options
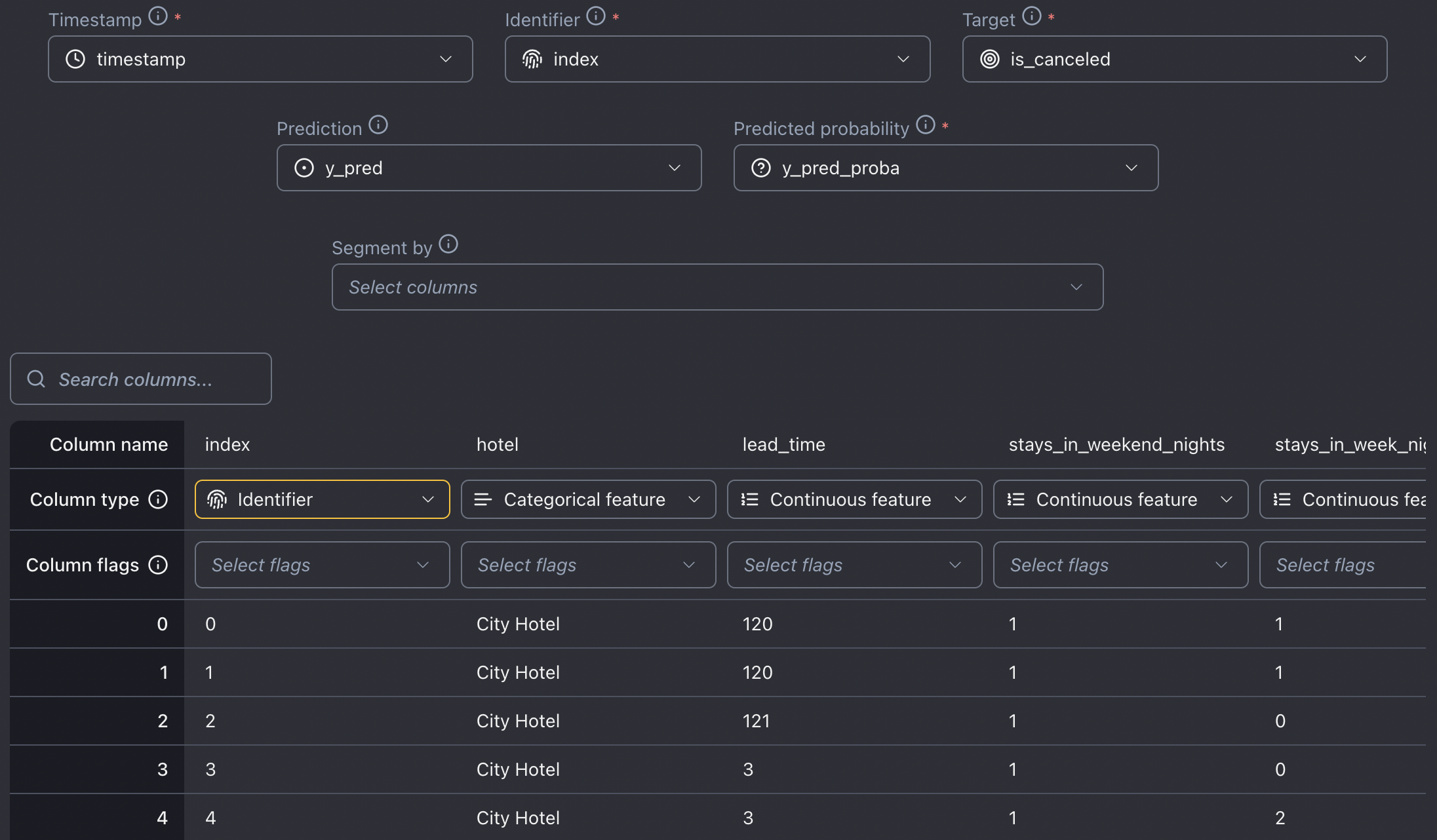
Reference dataset setup
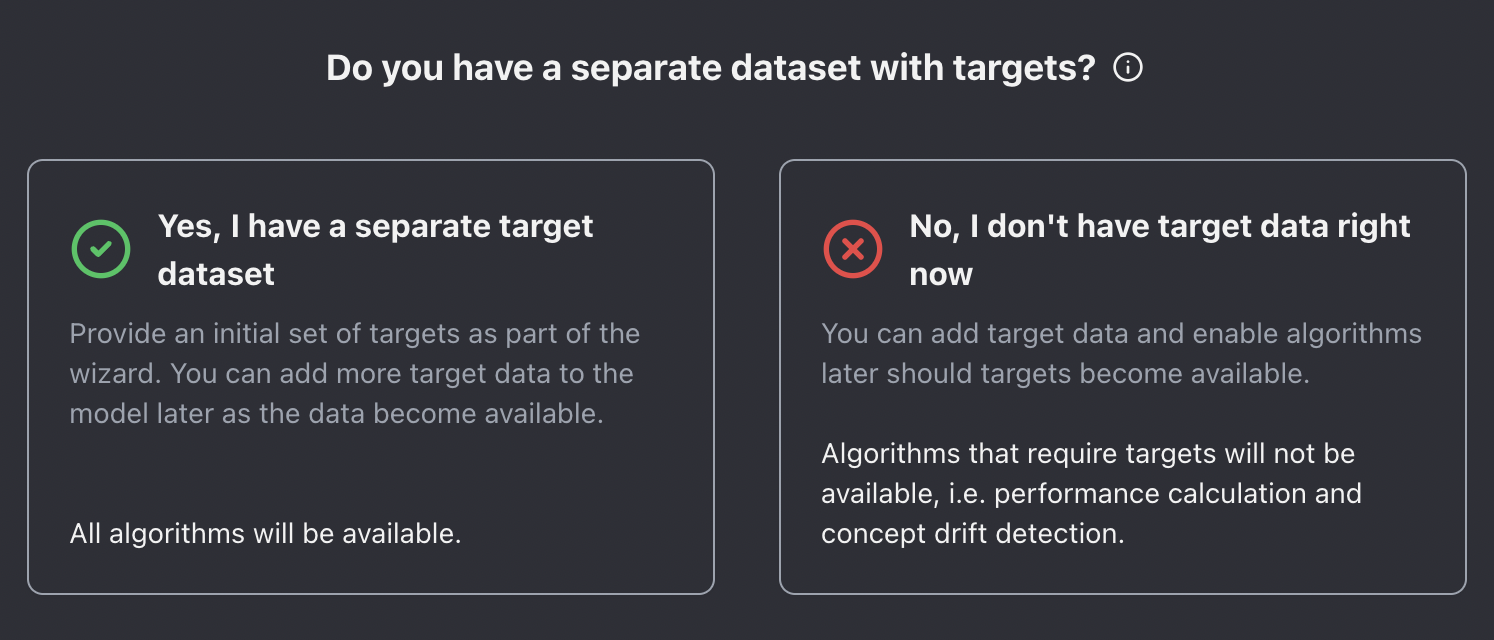
Upload target data if available
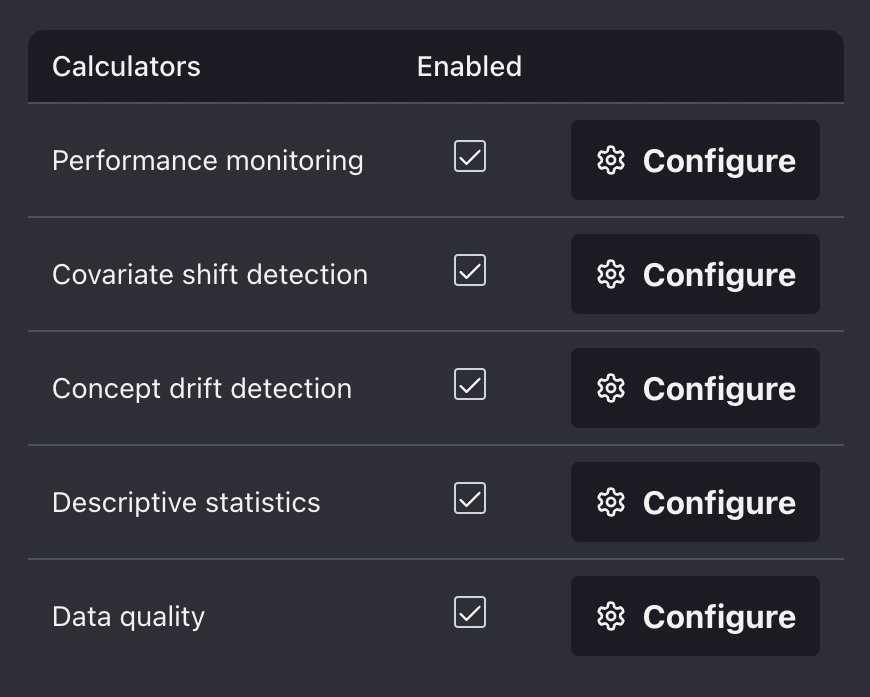
Metrics
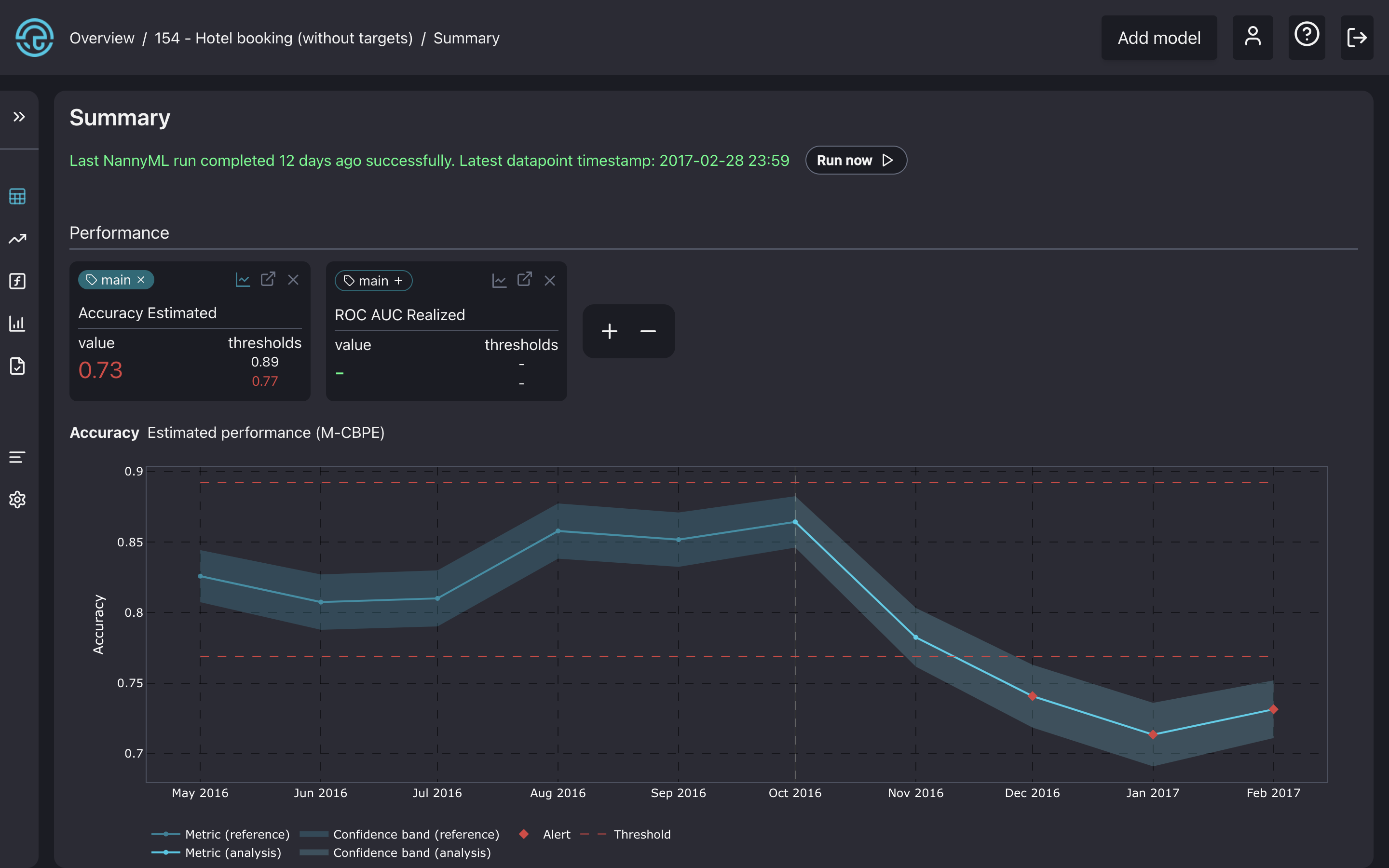
The accuracy plot in the model summary page.
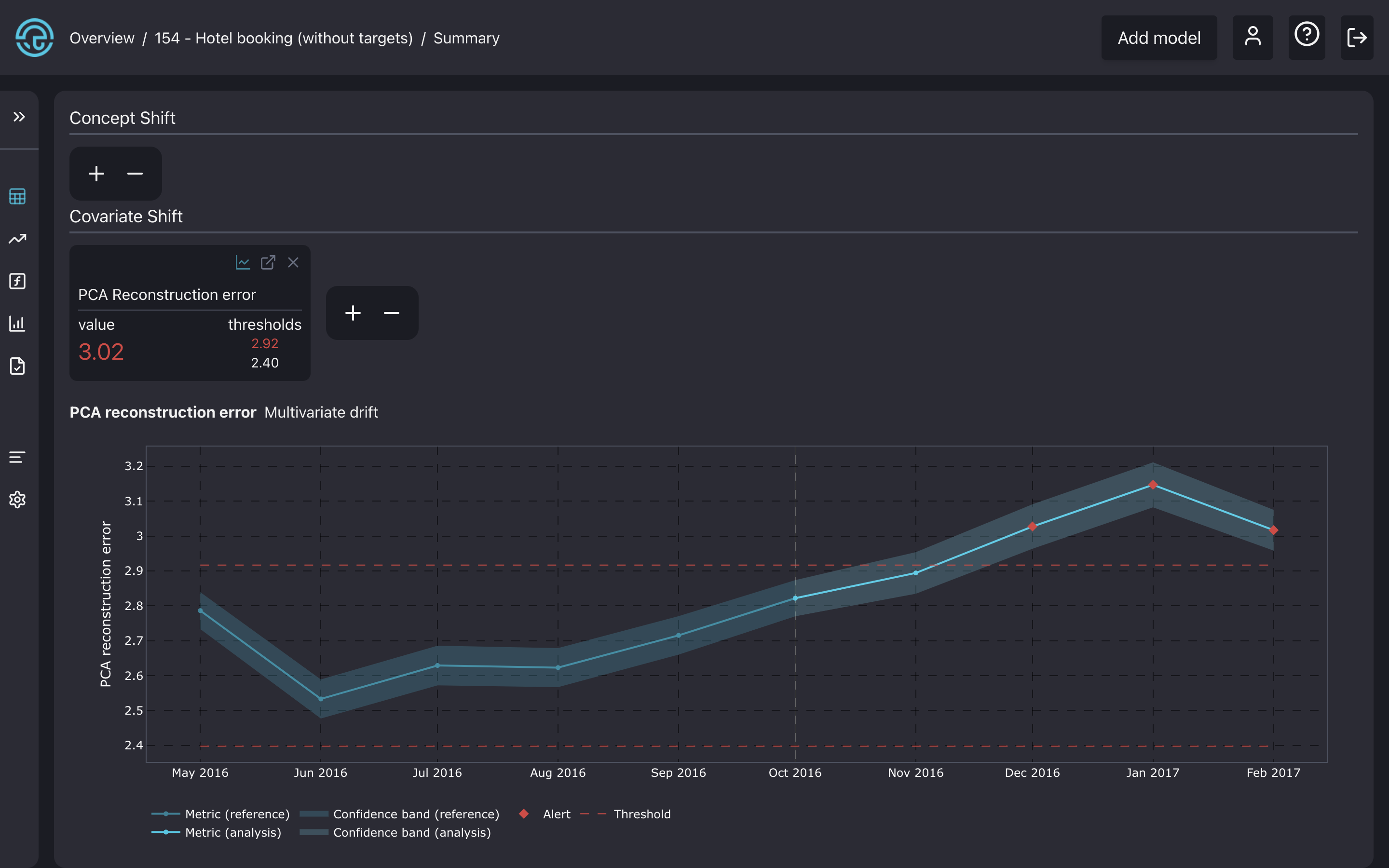
The PCA reconstruction error plot in the model summary page.
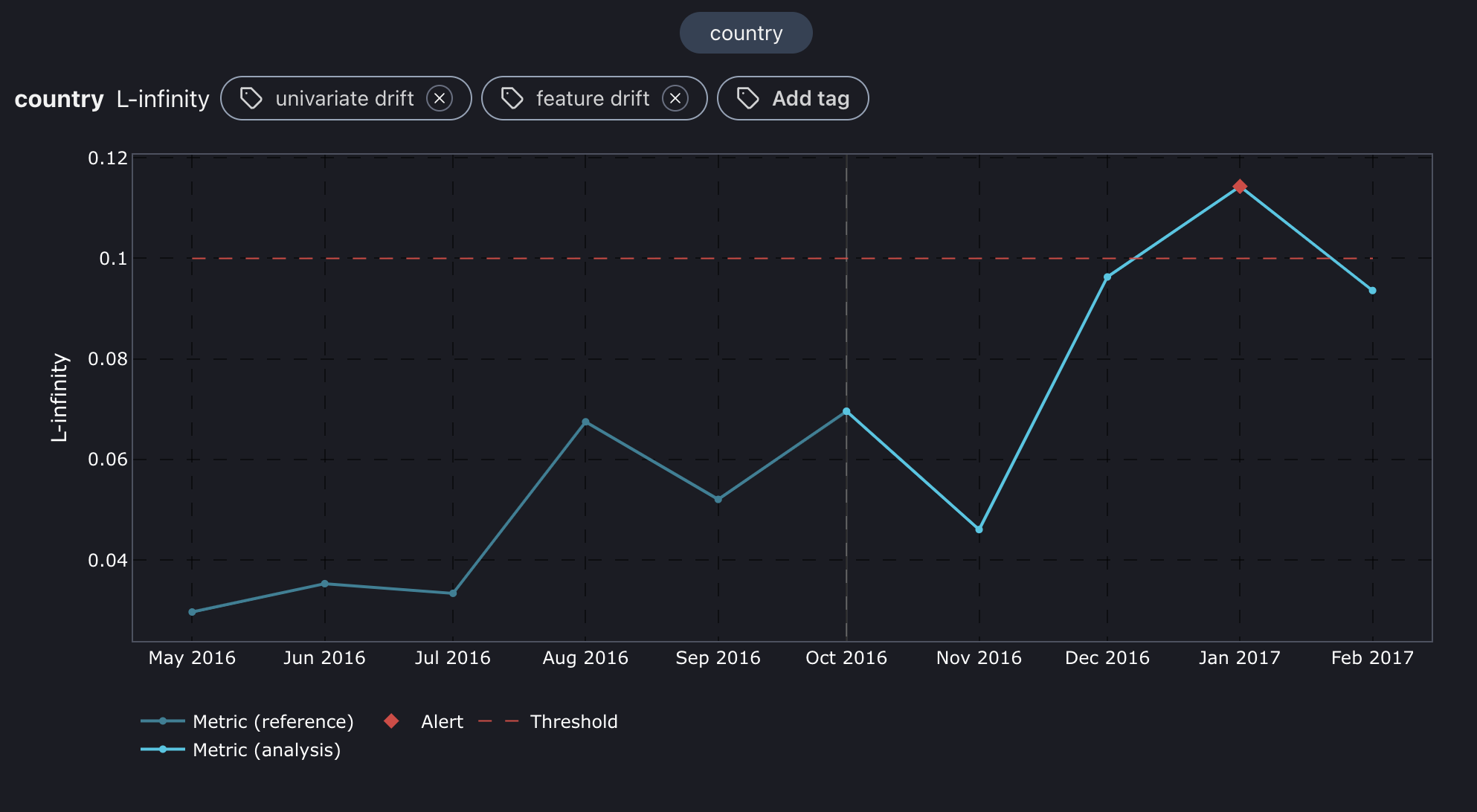
L-infinity plot for country feature.
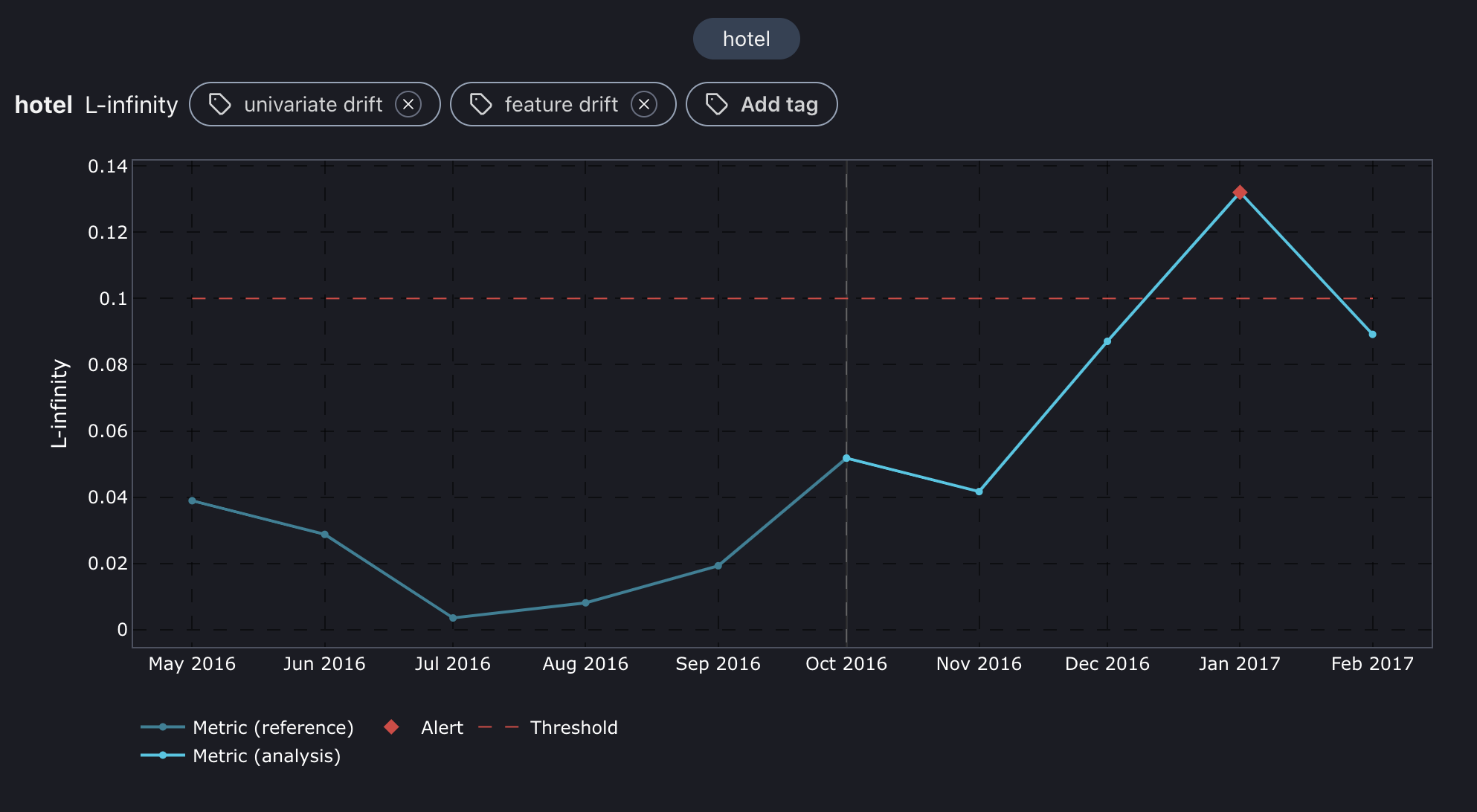
L-infinity plot for hotel feature.
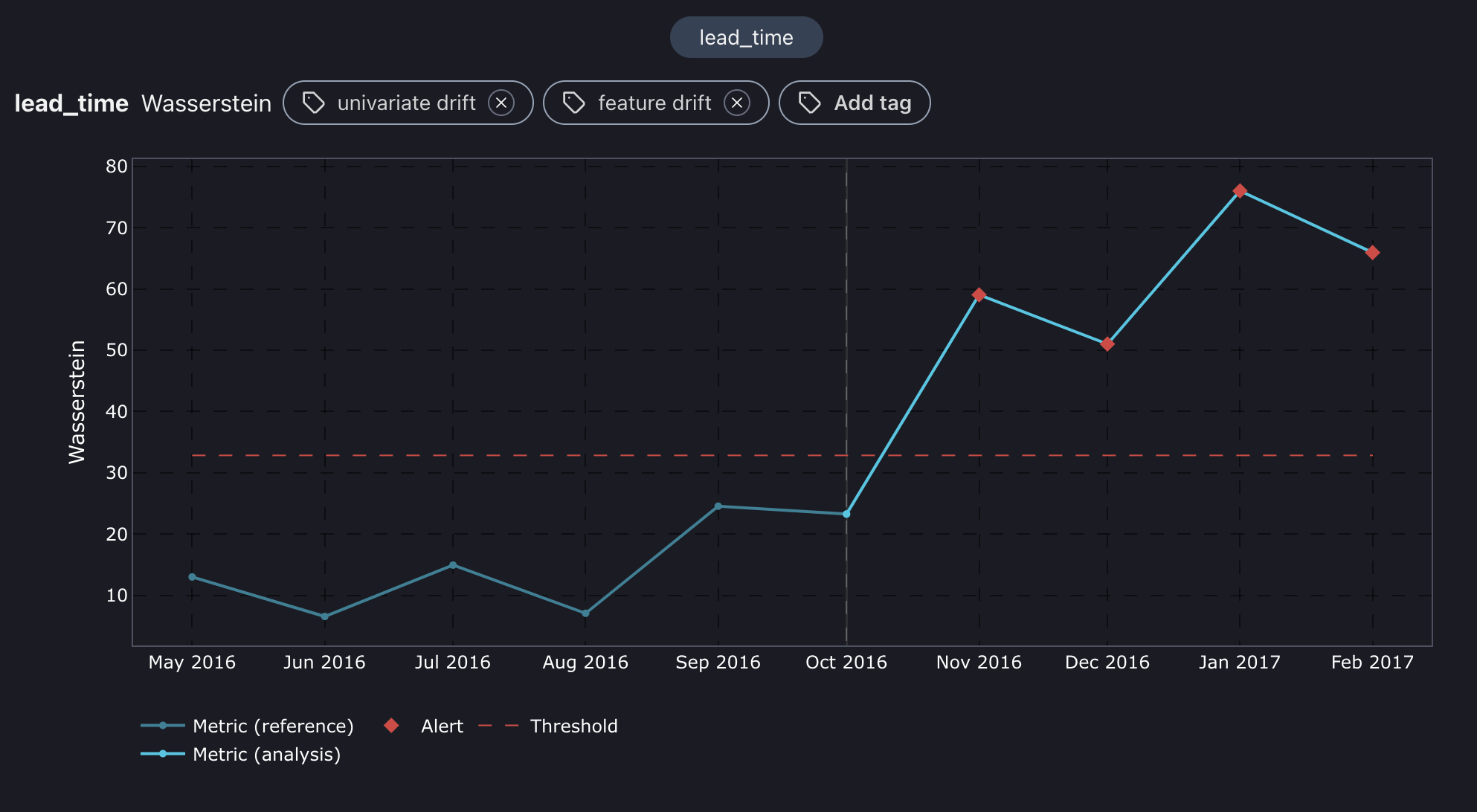
Wasserstein distance plot for lead_time feature.
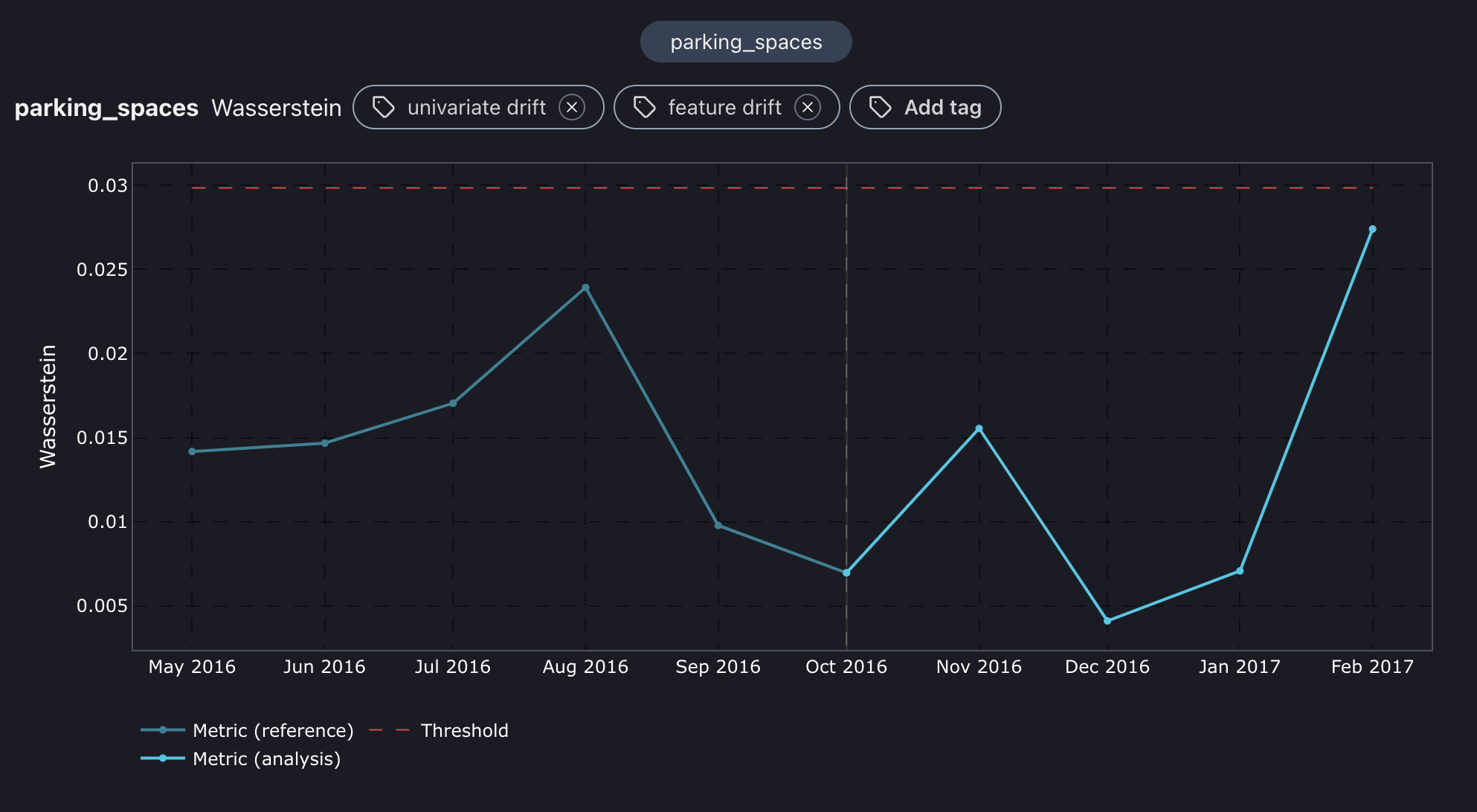
Wasserstein distance plot for parking_spaces feature.
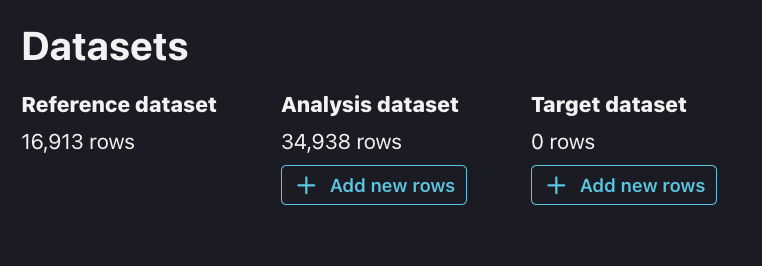
Datasets section in Model settings.
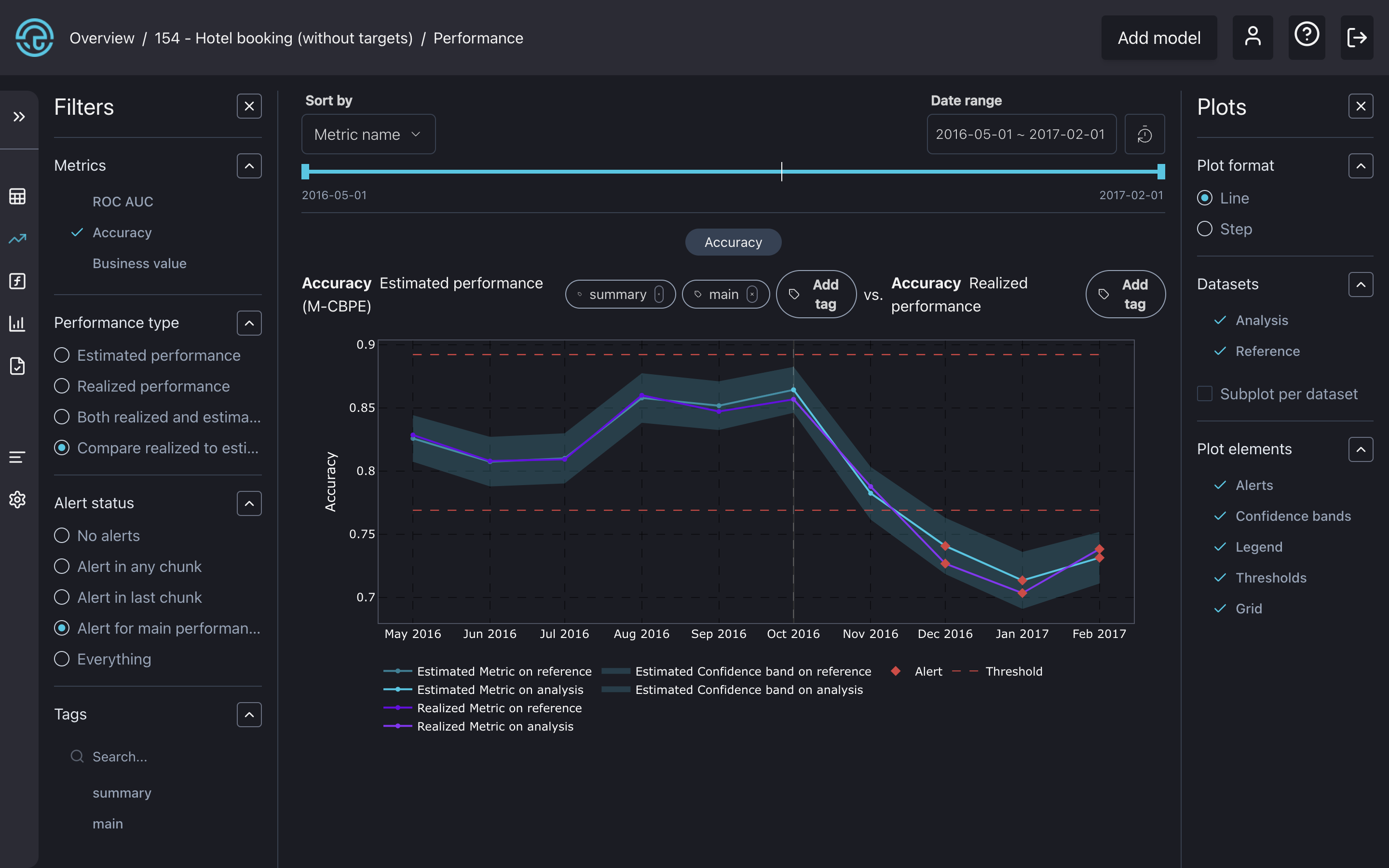
The performance dashboard with a comparison plot between realized and estimated performance.
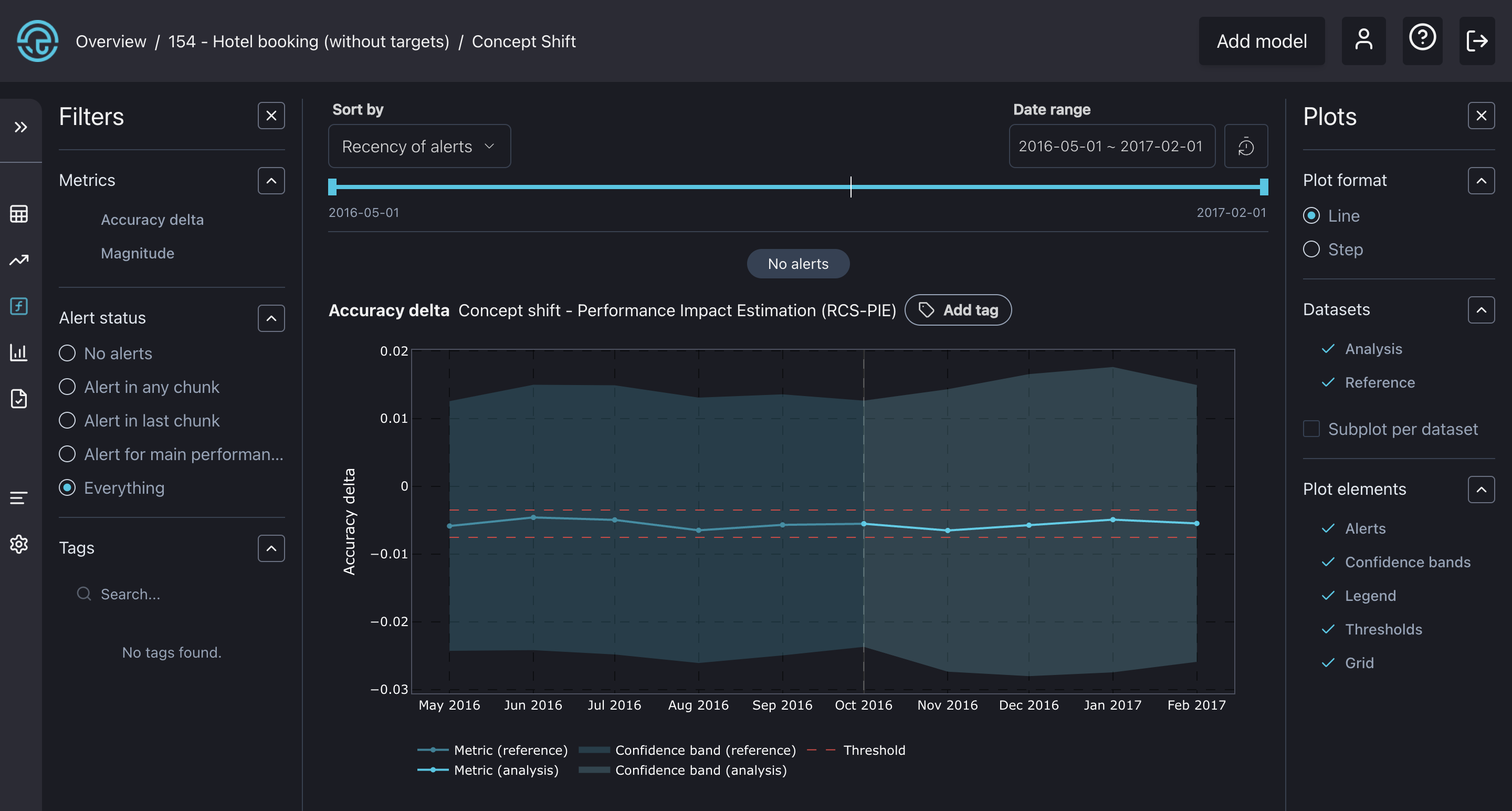
The concept drift dashboard with a plot showing the impact of concept drift on accuracy.
| 🧭 Product tour | Discover what else you can do with NannyML Cloud. |
| 🧑💻 Tutorials | Explore how to use NannyML Cloud with text and images |
| 👷♂️ Miscellaneous | Learn how the NannyML Cloud works under the hood |