Writing Functions for Binary Classification
Writing the functions needed to create a custom binary classification metric.
As we have seen on the Introductory Custom Metric page the key components of a custom binary classification metric are the specific Python functions we need to provide for the custom metric to work. Here we will see how to create them.
We will assume the user has access to a Jupyter Notebook running Python with the NannyML open-source library installed.
Sample Dataset
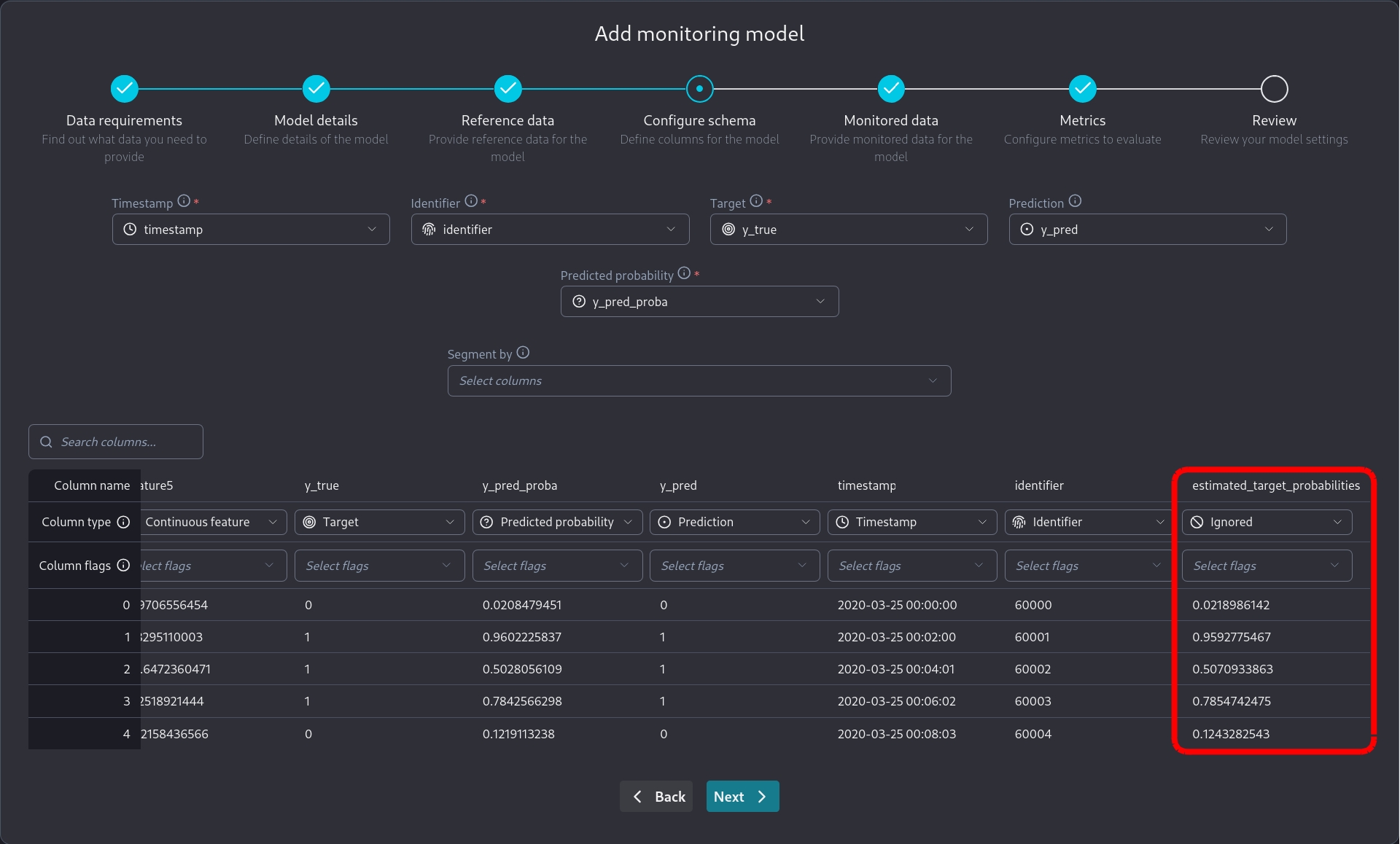
We have created a sample dataset to facilitate developing the code needed for custom binary classification metrics. The dataset is publicly accessible here. It is a pure covariate shift dataset that consists of:
5 numerical features:
['feature1', 'feature2', 'feature3', 'feature4', 'feature5',]Target column:
y_trueModel prediction column:
y_predThe model predicted probability:
y_pred_probaA timestamp column:
timestampAn identifier column:
identifierThe probabilities from which the target values have been sampled:
estimated_target_probabilities
We can inspect the dataset with the following code in a Jupyter cell:
Developing custom binary classification metric functions
NannyML Cloud requires two functions for the custom metric to be used. The first is the calculate function, which is mandatory, and is used to calculate realized performance for the custom metric. The second is the estimate function, which is optional, and is used to do performance estimation for the custom metric when target values are not available.
Custom Functions API
The API of these functions is set by NannyML Cloud and is shown as a template on the New Custom Binary Classification Metric screen.
Creating the calculate function is simpler and depends on what we want our custom metric to be. Let's describe the data that are available to us to create our calculate function.
y_true: Apandas.Seriespython object containing the target column.y_pred: Apandas.Seriespython object containing the model predictions column.y_pred_proba: Apandas.DataFramepython object containing the predicted probabilities column. This is a single-column dataframe for binary classification. It is a dataframe because in multiclass classification it contains multiple columns.chunk_data:Apandas.DataFramepython object containing all columns associated with the model. This allows using other columns in the data provided for the calculation of the custom metriclabels: A python list object containing the values for the class labels. Currently, for binary classification, only 0 and 1 are supported. This parameter is mostly for multiclass classification.class_probability_columns: A python list object containing the names of the class probability columns. In binary classification, this is a single-element list. This parameter is mostly for multiclass classification.estimated_target_probabilities: Apandas.DataFramepython object containing the calibrated predicted probabilities calculated from the predicted probabilities of the monitored model. This is a single-column dataframe for binary classification. It is a dataframe because in multiclass classification it contains multiple columns.**kwargs: You can use the keyword arguments placeholder to omit any parameters you don't actually require in your custom metric functions. This keeps your function signatures nice and clean. This also serves as a placeholder for future arguments in later NannyML cloud versions, intended to make the functions forward compatible.
Note that estimated_target_probabilities are calculated and provided by NannyML. The monitored model's predicted probabilities need not be calibrated for performance estimation to work.
To simulate this in the dataset we provided this column contains the probabilities from which the target values have been sampled. While using NannyML Cloud however the estimated_target_probabilities are estimated from the provided data.
Custom F_2 score
To create a custom metric from the F_2 score we would create the calculate function below:
While the calculate function of the F_2 score is straightforward this is not the case for the estimate function. In order to create an estimate function we need to understand performance estimation. Reading how CBPE works is enough to do so for classification problems. The key concept to understand are the estimated confusion matrix elements and how they are created. We can then use the functional form of the F_2 score to estimate the metric.
Putting everything together we get:
We can test those functions on the dataset loaded earlier. Assuming we run the functions as provided in a Jupyter cell we can then call them. Running calculate we get:
While running estimate we get:
We can see that the values between estimated and realized F_2 score are very close. This means that we are likely estimating the metric correctly. The values will never match due to the statistical nature of the problem. Sampling error will always induce some differences.
Testing a Custom Metric in the Cloud product
We saw how to add a binary classification custom metric in the Custom Metrics Introductory page. We can further test it by using the dataset in the cloud product. The datasets are publicly available hence we can use the Public Link option when adding data to a new model.
Reference Dataset Public Link:
Monitored Dataset Public Link:
The process of creating a new model is described in the Monitoring a tabular data model.
We need to be careful to mark estimated_target_probabilities as an ignored column since it's related to our oracle knowledge of the problem and not to the monitored model the dataset represents.
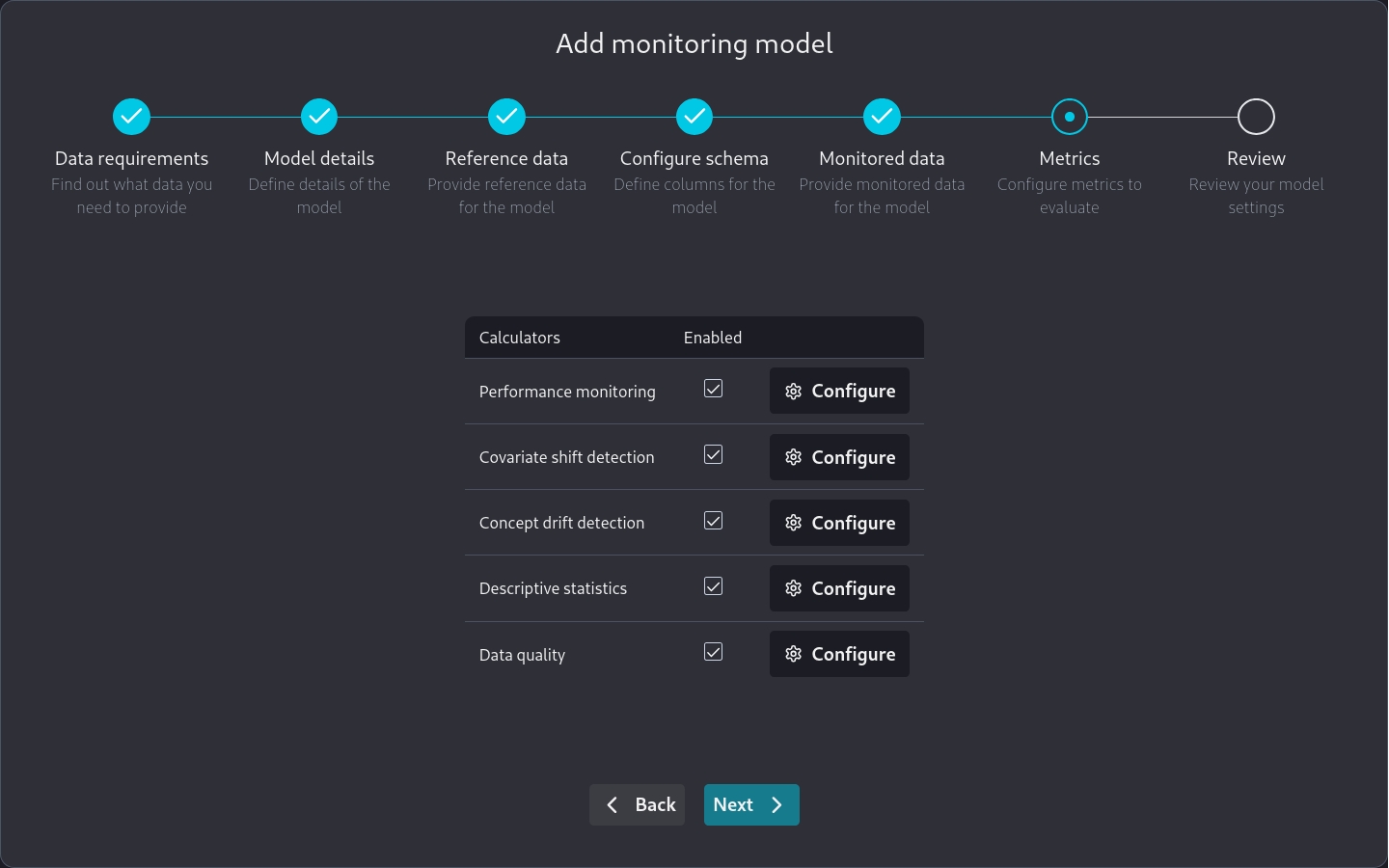
Note that when we are on the Metrics page
we can go to Performance monitoring and directly add a custom metric we have already specified.
After the model has been added to NannyML Cloud and the first run has been completed we can inspect the monitoring results. Of particular interest to us is the comparison between estimated and realized performance for our custom metric.
We see that NannyML can accurately estimate our custom metric across the whole dataset. Even in the areas where there is a performance difference. This means that our calculate and estimate functions have been correctly created as the dataset is created specifically to facilitate this test.
You may have noticed that for custom metrics we don't have a sampling error implementation. Therefore you will have to make a qualitative judgement, based on the results, whether the estimated and realized performance results are a good enough match or not.
Next Steps
You are now ready to use your new custom metric in production. However, you may want to make your implementation more robust to account for the data you will encounter in production. For example, you can add missing value handling to your implementation.